新电脑到了,自然少不了本地搭建一套本地大模型环境了,毕竟16G的显存还是嘎嘎抗揍的。之前用的比较多的是使用ollama搭建,不过看了最近比较火的 llama.ccp之后决定尝试看看, 学习 llama.cpp 时,不用深究底层原理、复杂编译优化和模型量化细节,日常 90% 的落地场景,都是用 CLI 命令行快速推理 + Server 搭建 HTTP 接口服务。废话少说,直接讲官方核心能力:llama-cli 命令行工具、llama-server 轻量化 HTTP 服务,基于最新官方文档与实践经验,整理全量参数、实操命令、接口示例、生产模板、调优避坑,开箱即用,适合本地推理、接口开发、私有化部署。以下内容大多部分为手动实践,当然也有实践不了的部分,比如多卡之类的参数,这里就只做个记录,万一日后能用呢~
一、基本认识
1.1 核心认知
llama.cpp 两大核心工具:
llama-cli:终端命令行工具,用于单次推理、多轮对话、本地快速测试,轻量无依赖
llama-server:内置高性能 HTTP 服务,支持 WebUI、OpenAI 兼容 API、多并发、流式输出、RAG 嵌入、重排序、多模态、函数调用,是生产落地首选
唯一硬性要求:准备 GGUF 格式量化模型(推荐 Q4_K,平衡速度 / 显存 / 精度),可自行转换或 HuggingFace 或 ModelScope 直接下载成品。接下来将以 HuggingFace 中下载的 Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf 模型为例,下面mmproj开头的也一并下载,这样才支持多模态。
1.2 源码部署
# 拉取源码 & 同步子模块
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp && git submodule update --init --recursive
# 按需编译(选其一)
make CUDA=1 # NVIDIA 显卡加速(推荐)
make METAL=1 # Mac 苹果芯片加速
make # 纯 CPU 编译(通用)
# 验证
./llama-cli --version
./llama-server --version
1.3 版本部署
访问版本发布页面下载对应版本:Releases · ggml-org/llama.cpp , 我这里选的是 cuda13.3,因为我通过 nvidia-smi 命令查得本机版本为13.2
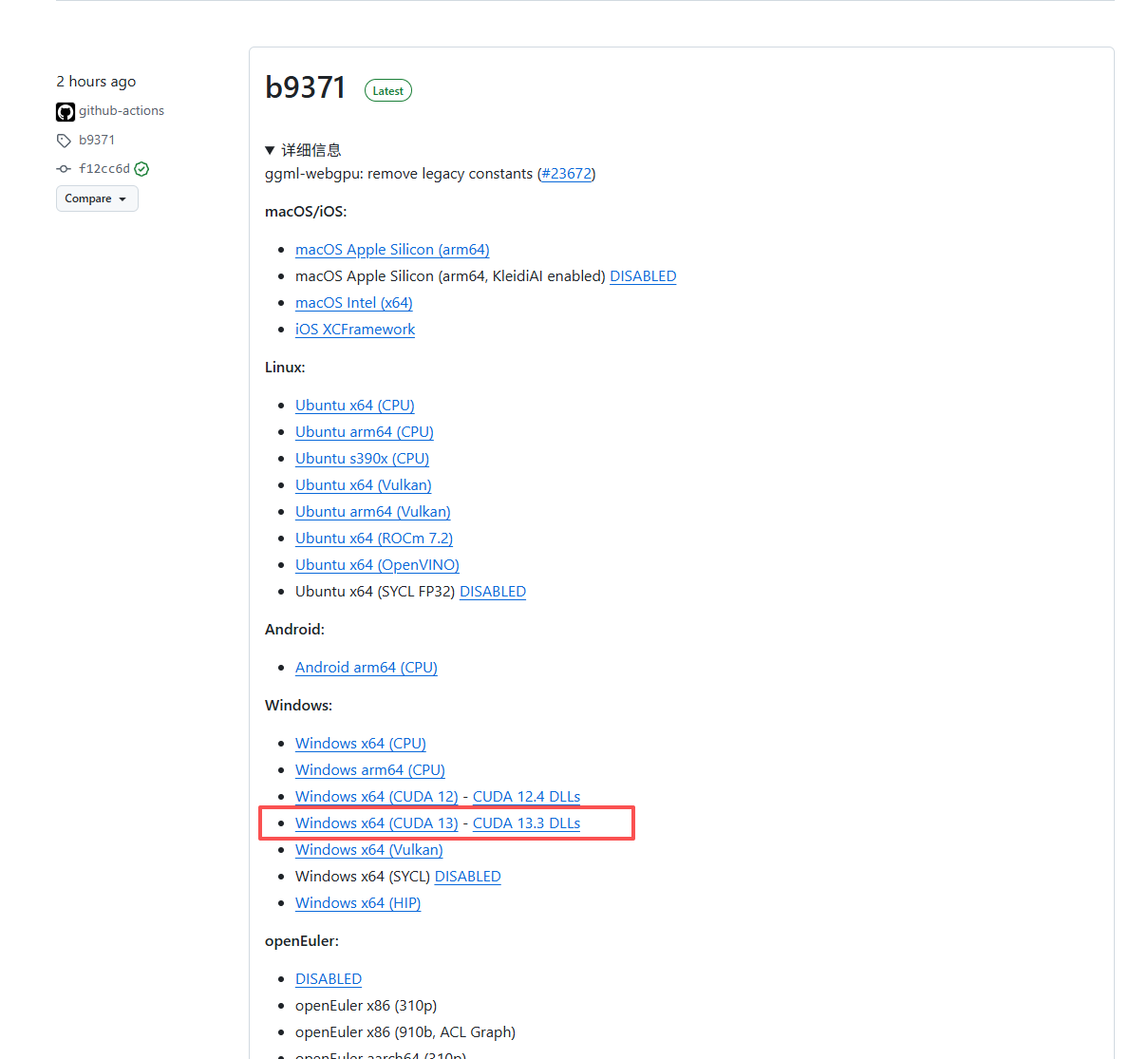
下载后解压到无中文目录中即可。
二、llama-cli 完整实战(命令行)
2.1 基础核心参数(高频必记)
2.2 高频场景命令
场景 1:单次问答
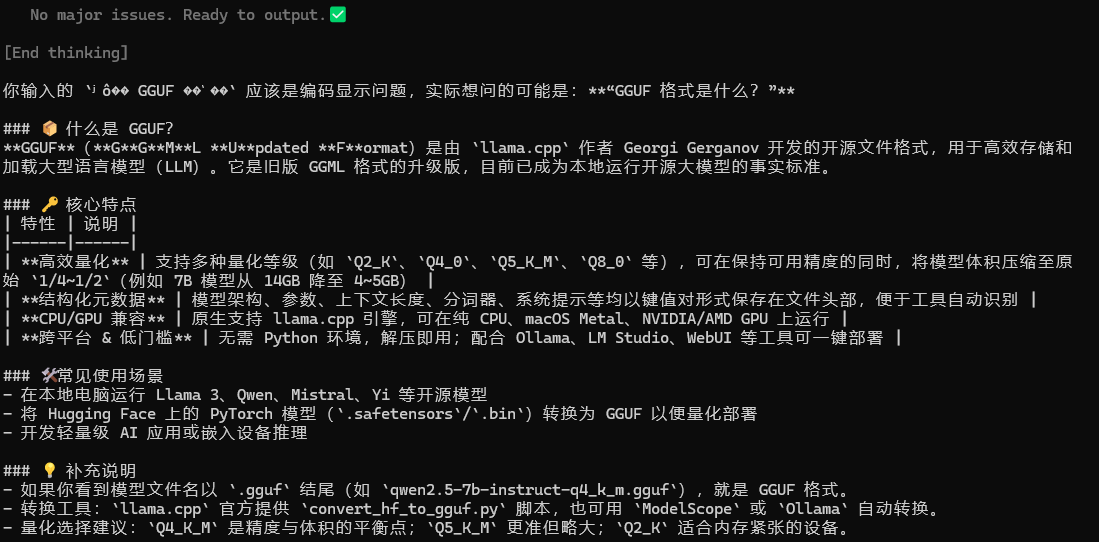
llama-cli.exe -m E:\\data\\ai\\model\\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf -c 2048 -p "什么是 GGUF 格式?"
场景 2:交互式对话
llama-cli.exe -m E:\\data\\ai\\model\\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf -c 4096 --interactive场景 3:代码生成(低随机)
llama-cli.exe -m E:\\data\\ai\\model\\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf -c 2048 --temp 0.2 --repeat-penalty 1.1 -p "写一个 Python 批量重命名脚本"
2.3 进阶采样(解决重复 / 发散)
--min-p 0.05:过滤低概率垃圾 token--mirostat 2:自适应困惑度,长文本更稳定--presence-penalty 0.1:抑制重复主题
三、llama-server 全量实战(HTTP 服务)
3.1 参数全景(官方 7 大类,精简高频)
1)模型加载
-m, --model:本地 GGUF 路径-hf, --hf-repo:直接从 HF 下载(例:bartowski/Qwen3-8B-GGUF:q4_k_m)
2)上下文与批处理
-c, --ctx-size:上下文(8B 模型建议 8192)-b, --batch-size:逻辑批处理(2048)-ub, --ubatch-size:物理批处理(显存不足调小)
3)GPU / 显存优化
-ngl, --n-gpu-layers:GPU 卸载(999 = 全载)-ctk q4_0, -ctv q4_0:KV 缓存量化(显存直降 75%)-fa, --flash-attn:长上下文加速(强烈推荐)
4)并发调度
-np, --parallel:并发槽位(多用户)--cont-batching:连续批处理(默认开启,提升吞吐)
5)采样控制
--temp、--top-k、--top-p、--repeat-penalty:同 CLI--json-schema:强制输出合法 JSON
6)网络与安全
--host 0.0.0.0:开放外网访问--port 8080:端口--api-key:接口鉴权
7)高级能力
--embedding:开启向量嵌入(RAG)--reranking:开启重排序--mmproj:多模态图文模型
3.2 最简启动(本地测试)
llama-server.exe -m E:\\data\\ai\\model\\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf --mmproj E:\\data\\ai\\model\\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf -c 8192 -ngl 999
浏览器打开:http://127.0.0.1:8080(内置 WebUI)
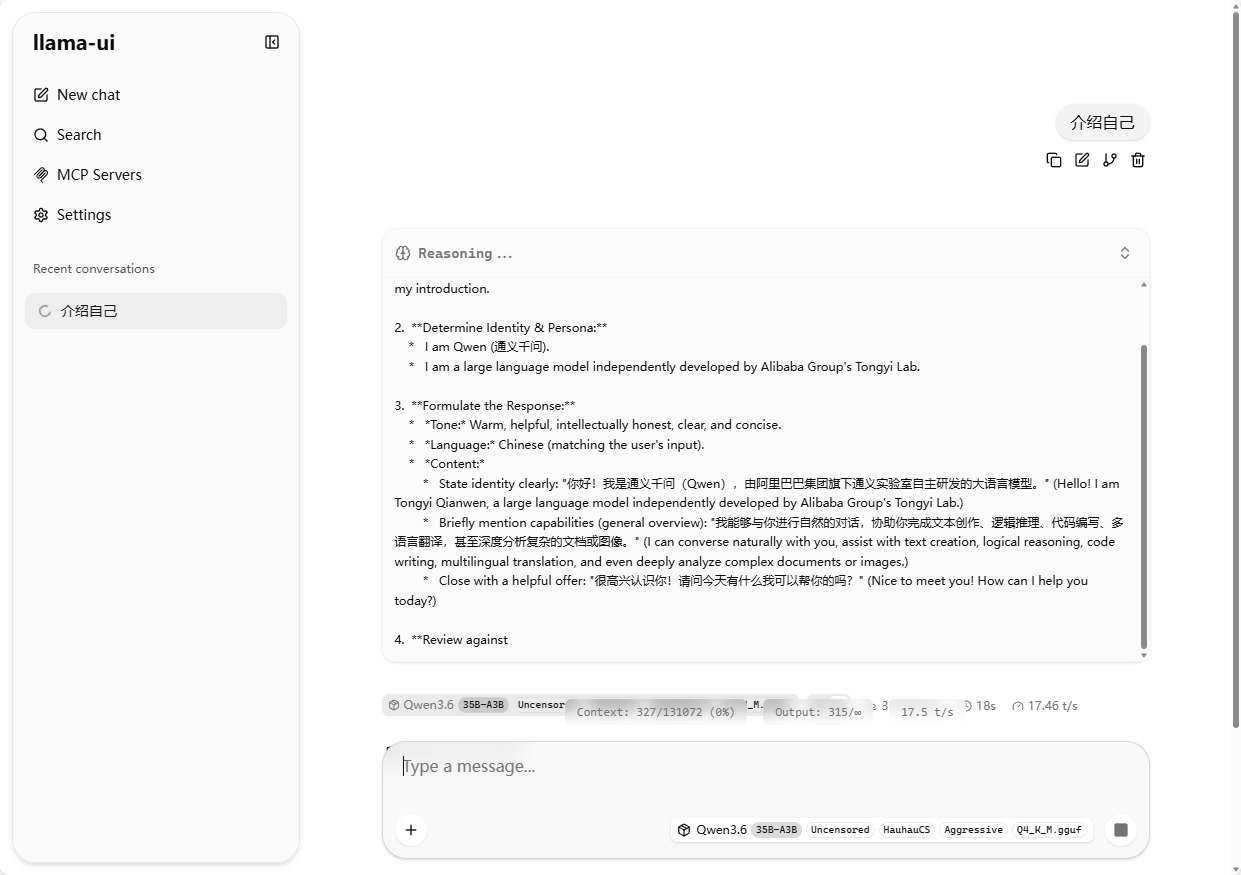
3.3 生产级启动模板(开放 + 并发 + 加速)
llama-server.exe \
-m E:\\data\\ai\\model\\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf \
--mmproj E:\\data\\ai\\model\\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf \
-c 8192 \
-ngl 999 \
-ctk q4_0 -ctv q4_0 \
-fa on \
-np 4 \
--host 0.0.0.0 \
--port 8080 \
--api-key sk-xxx \
--log-disable
3.4 核心 API(兼容 OpenAI)
健康检查
curl http://127.0.0.1:8080/health对话(/v1/chat/completions)
curl -X POST http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local-llm",
"messages": [{"role":"user","content":"介绍 llama-server"}]
}'
向量嵌入(RAG)
curl -X POST http://127.0.0.1:8080/v1/embeddings \
-d '{"input":"需要向量化文本"}'
3.5 实用配置模板(直接复制)
1)入门(8B + 单卡)
llama-server.exe \
-hf bartowski/Qwen3-8B-GGUF:q4_k_m \
-ngl 999 -c 8192 -np 2 --host 0.0.0.0
2)长上下文(128K)
llama-server.exe \
-m xxx-q4_k.gguf \
-c 131072 \
-ctk q4_0 -ctv q4_0 \
-fa on \
--rope-scaling yarn --rope-scale 16
3)多卡 70B
llama-server.exe \
-m xxx-q4_k.gguf \
-ngl 999 \
-sm tensor -ts 0.5,0.5 \
-dev gpu0,gpu1 \
-c 32768
四、性能调优与避坑(官方最佳实践)
4.1 显存紧张优先做
-c降至 4096/2048KV 缓存设为
q4_0降低
-ngl,部分层放 CPU
4.2 速度优先
开启
--flash-attn增大
-b、-ub开启
--speculative投机解码
4.3 高频坑
外网访问失败:没加
--host 0.0.0.0输出乱码 / 循环:调高
repeat-penalty、降低temp内存溢出:减小上下文、启用 KV 量化
五、总结
llama.cpp 的落地核心就是 llama-cli 快速验证 + llama-server 生产部署。CLI 轻量无依赖,适合临时测试;Server 能力全面、兼容 OpenAI、支持并发 / 嵌入 / 多模态,覆盖 99% 私有化场景。部署完大模型下一步就是 Hermes了!